Query GTFS Parquet Data in the Browser with DuckDB-Wasm
GTFS data is typically served though traditional relational database systems such as PostGreSQL or SQlite. Using DuckDB and Parquet opens the door for analyzing GTFS data in the browser using a cloud native data format.
The General Transit Feed Specification (GTFS) is an open standard used by over 10,000 transit agencies in 100 countries. Published as a collection of csv files, it’s typically loaded into a relational database for complex queries, supporting APIs and visualizations in front end applications. Numerous excellent tools have been developed to help in the ETL process including gtfs-via-postgres, node-gtfs and others. A number APIs have also been created that serve GTFS data including OpenMobilityData and Transitland. However, these services can be expensive to build, maintain and operate.
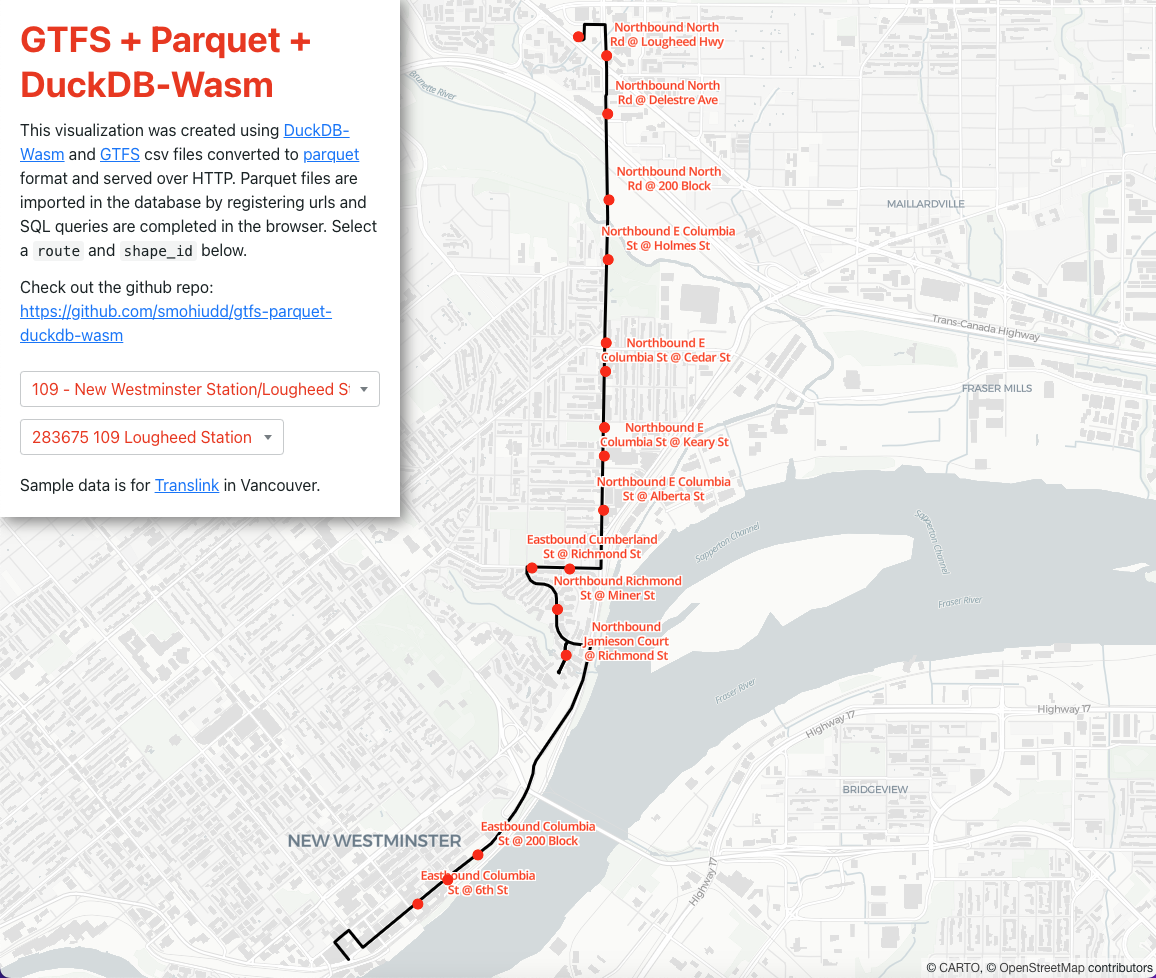 http://saadiqm.com/gtfs-parquet-duckdb-wasm/
http://saadiqm.com/gtfs-parquet-duckdb-wasm/
The development of tools such as DuckDB and support for Parquet files, provides an exciting opportunity to experiment with potential cloud native analysis and visualization of GTFS data.
DuckDB, known formally as an in-process Online analytical processing (OLAP) database system allows for complex, long-running SQL queries such as aggregations or joins on large datasets by using vectorized operations. The result is extremely fast analytical queries compared to traditional systems which have higher overhead.
The Parquet file format is an open source column oriented data file that provides efficient data compression. Compared to row based files like CSV, column oriented formats like Parquet allow you to skip over non-relevant data quickly. For GTFS CSV files, converting to Parquet means greatly decreased file sizes. DuckDB supports both reading and writing Parquet files, while querying Parquet files is extremely fast because of filter and projection pushdown which results in partial reads of the file for efficiency.
The release of DuckDB-Wasm is an exciting advancement in allowing analysis workloads in the browser with the help of WebAssembly. Parquet files can be read locally or from a remote server and support partial query of only the required bytes of data. The CMU Data Interaction team also created a useful DuckDBClient in Observable to create, connect and query a DuckDB-Wasm database.
I wanted to see how I could use DuckDB-Wasm and GTFS Parquet files to query and visualize trip shapes and stops. Using a single page React application and maplibre-gl-js the process involved using the DuckdBClient to instantiate DuckDB-Wasm and then registering parquet urls to the local filesystem:
await db.registerFileURL("trips.parquet", url, duckdb.DuckDBDataProtocol.HTTP, false);
And then using parquet_scan to create a view:
const conn = await db.connect();
await conn.query(`
CREATE VIEW IF NOT EXISTS 'trips.parquet'
AS SELECT * FROM parquet_scan('trips.parquet')`
);
await conn.close();
DuckDB has a spatial extension that allows for geospatial data processing however this is not available in DuckDB-Wasm. To overcome this I simply used the Turf.js library to create a GeoJSON featureCollection which was then passed to maplibre.
Three sets of SQL queries were used to list all distinct trip shapes, get trip shape coordinates and get stop location coordinates:
//List all distinct shapes:
db.queryStream(`
SELECT DISTINCT ON (shape_id) shape_id, trip_id, trip_headsign
FROM 'trips.parquet' WHERE route_id=${routeId}
`)
//Get shape coordinates
db.queryStream(`
SELECT shape_pt_sequence, shape_pt_lat, shape_pt_lon FROM
(SELECT * FROM trips.parquet
WHERE trip_id=${tripId}) as b
JOIN shapes.parquet ON b.shape_id=shapes.shape_id
ORDER BY shape_pt_sequence
`)
//Get stop locations
db.queryStream(`
SELECT b.stop_id, stop_lat, stop_lon, stop_name FROM
(SELECT stop_id, stop_sequence FROM stop_times.parquet
WHERE trip_id=${tripId}
ORDER BY stop_sequence) as b
JOIN stops.parquet ON b.stop_id=stops.stop_id
` )
Please check out the repo for more details of this implementation: https://github.com/smohiudd/gtfs-parquet-duckdb-wasm
The result is a snappy visualization that directly queries GTFS Parquet files without the need to setup a PostGreSQL database or an API service, allowing the possibility of analyzing GTFS data using cloud native applications.